Machine Learning Supervision Optional
Machine learning is defined as a subfield of computer science and artificial intelligence which “gives computers the ability to learn without being explicitly programmed” (source).
Although the statistical techniques which underpin machine learning have existed for decades recent developments in technology such as the availability/affordability of cloud computing and the ability to store and manipulate big data have accelerated its adoption. This essay is meant to explore the most popular methods currently being employed by data scientists such as supervised and unsupervised methods to people with little to no understanding of the field.
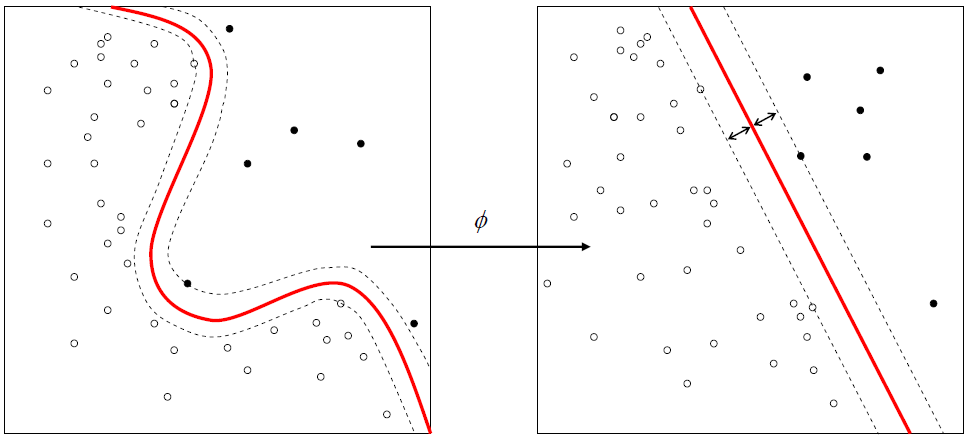 (An example of a support vector machine (SVM) algorithm being used to create a decision boundary (via wikipedia)
(An example of a support vector machine (SVM) algorithm being used to create a decision boundary (via wikipedia)
{kind=link}
Supervised
Supervised machine learning describes an instance where inputs along with the outputs are known. We know the beginning and the end of the story and the challenge is to find a function (story teller, if you will) which best approximates the output in a generalizable fashion.
Example: Imagine a doctor trying to predict whether someone has HIV. He has the test results (outputs) and medical records (variables) for patients who have tested positive and negative for the disease. His task is to look at the records and develop a decisioning system so that when a new patient arrives, given just their medical record (variables) he can accurately predict whether or not they are HIV positive.
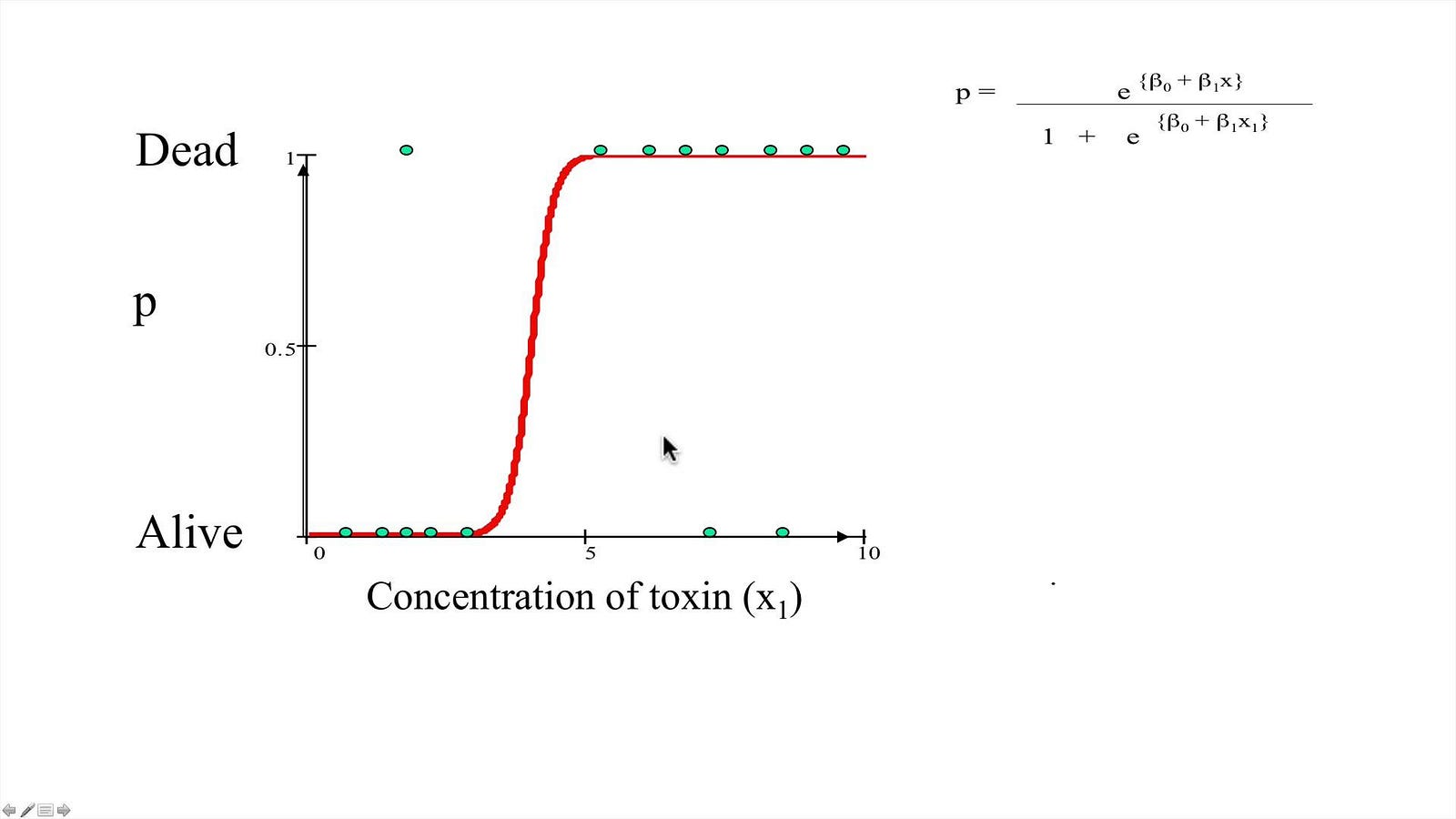 (A graphic represention a logistic regression)
(A graphic represention a logistic regression)
Unsupervised
Unsupervised machine learning is a bit more abstract because it describes a scenario in which only know the input variables are known but nothing about the outputs are known. A typical task for this type of machine learning is clustering, or grouping the data by using features, to arrive at generalizable insights.
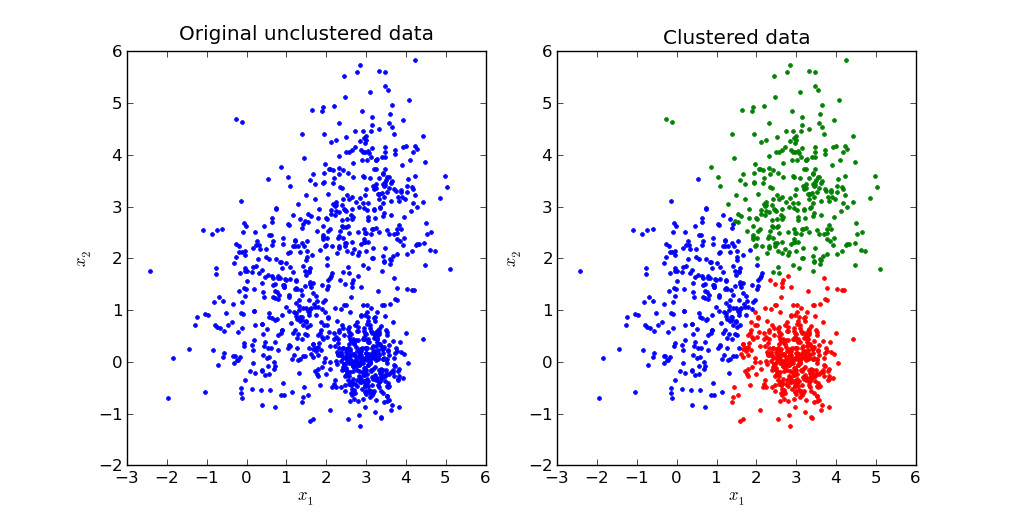 Clustering using K-Nearest Neighbors algorithm
Clustering using K-Nearest Neighbors algorithm
Semi-Supervised
Semi-supervised learning is a hybrid of supervised and unsupervised machine learning. This describes a scenario where there is a small portion of labeled data mixed with unlabeled data. Acquiring labeled data is costly because typically it requires manual input from humans to generate. Semi-supervised learning allows for quicker turn-around while sacrificing accuracy (increasing labeled data increases model accuracy) but it is usually more accurate than unsupervised learning alone.
Reinforcement learning
Reinforcement learning, or simulation based optimization is a relatively lesser known branch of machine learning but where the future of AI is headed because it requires almost no human input. It’s also what enabled Google’s Alpha Go to be so successful—and which we’ll use for illustrative purposes (here’s the research paper).
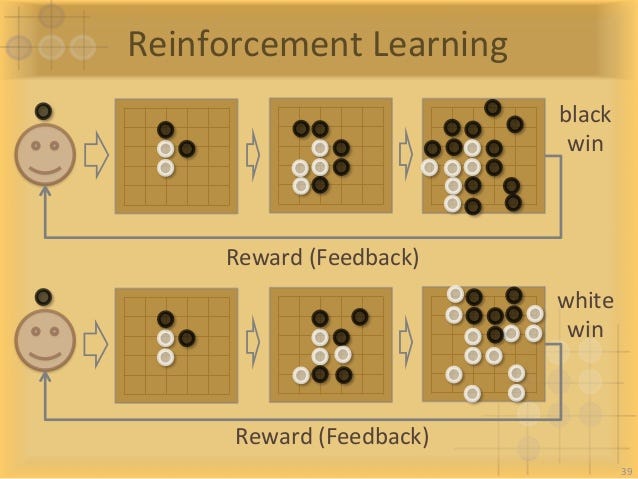
Reinforcement learning describes a situation in which humans provide the following:
- An environment (A Go board)
- A set of rules (The rules of Go)
- A Set of actions (All the actions that can be taken)
- A set of outcomes (Win or lose)
Then given an environment, rules, actions and outcomes a computer can repeatedly simulate many, many games of Go and "learn" (optimzie) for what strategies work best in a given scenario.
What makes reinforcement learning extremely powerful is the sheer number of times a computer can simulate unique games. By the time Alpha Go faced Lee Sedol, the top player in the world, it had simulated more games than Sedol could’ve ever hoped to play in his lifetime. Humans need to eat, sleep and take breaks, computers don’t they just require electricity. There you have it, a quick and dirty overview of some of the more popular machine learning methods currently being employed.
Follow me on medium to show your support!